Migrate your connections (1/4)
Data access in RapidMiner
The RapidMiner platform includes connection objects that give workflows access to external data. Supported external data sources include:
- traditional JDBC databases,
- NoSQL,
- cloud repositories (S3, Azure DataLake, Google BigData, Salesforce),
- some industry-specific, like SensorLink, and
- many others.
All these connections are now available in the cloud. Connections belong to projects and they can be used in Designer workflows.
Roadmap for connections
RapidMiner Cloud is a growing platform. We started small back in May, and we're adding new features every day. Data access is one of the most important aspects, as it to a large extent determines which use cases can be solved in the cloud, and which ones not yet.
We plan to incorporate connectivity in 4 phases, and we have now completed phase 1:
- Phase 1: connections are available, but the user still needs Studio to create and edit them (complete).
- Phase 2: it will be possible to add and edit connections directly in the cloud.
- Phase 3: connections will be shareable among multiple users and projects.
- Phase 4: it will be possible to create connection templates which can be shared in a secure way without credentials or other sensitive data.
Create or edit a connection (phase 1)
Currently, to create a connection on our cloud platform, you proceed in two steps:
-
If the connection does not yet exist in RapidMiner Studio, create the connection.
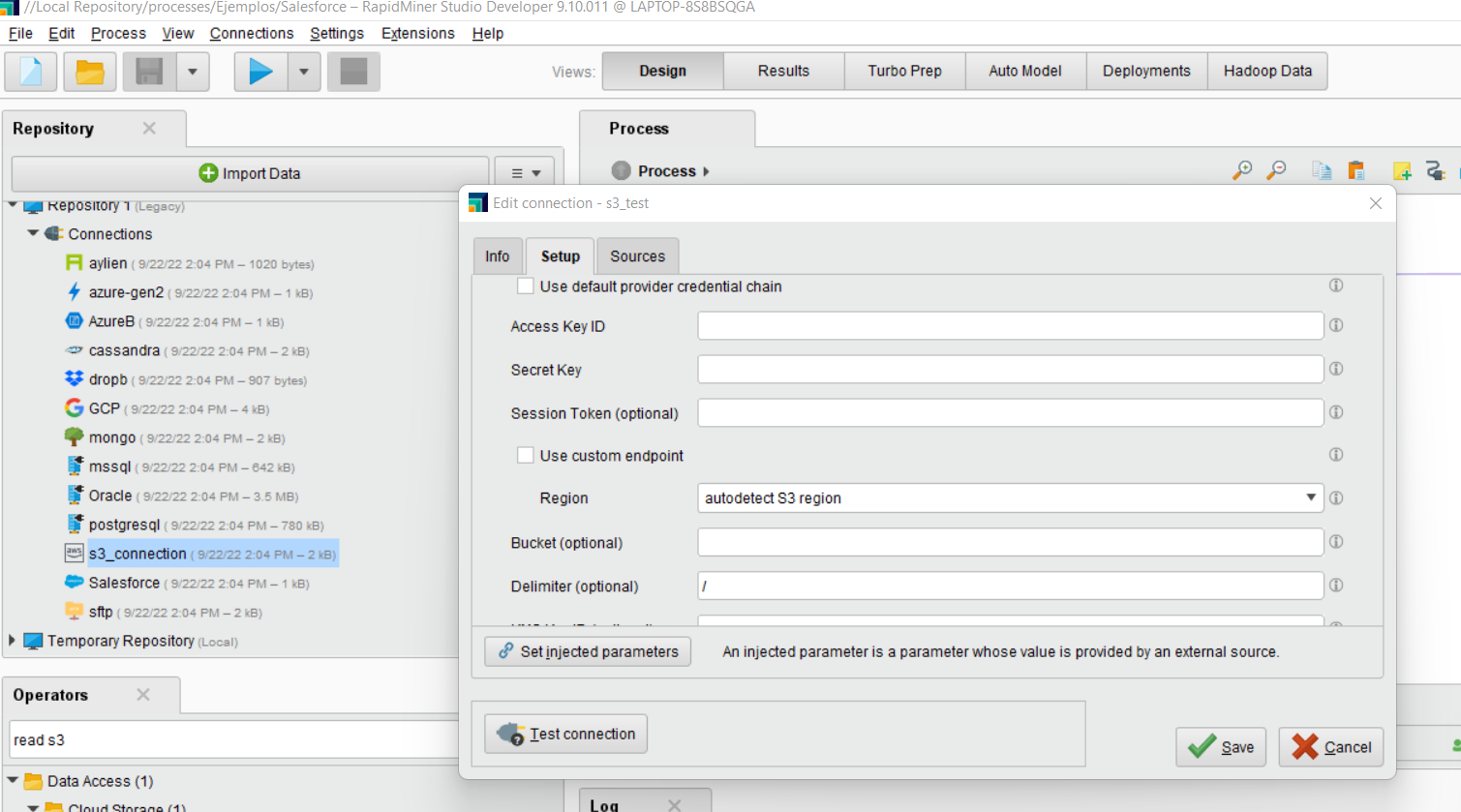
-
Once the connection is created, use the migration tool to transfer it to the cloud. You'll need to select an already existing cloud project, because in phase 1 connections are tied to a single project.
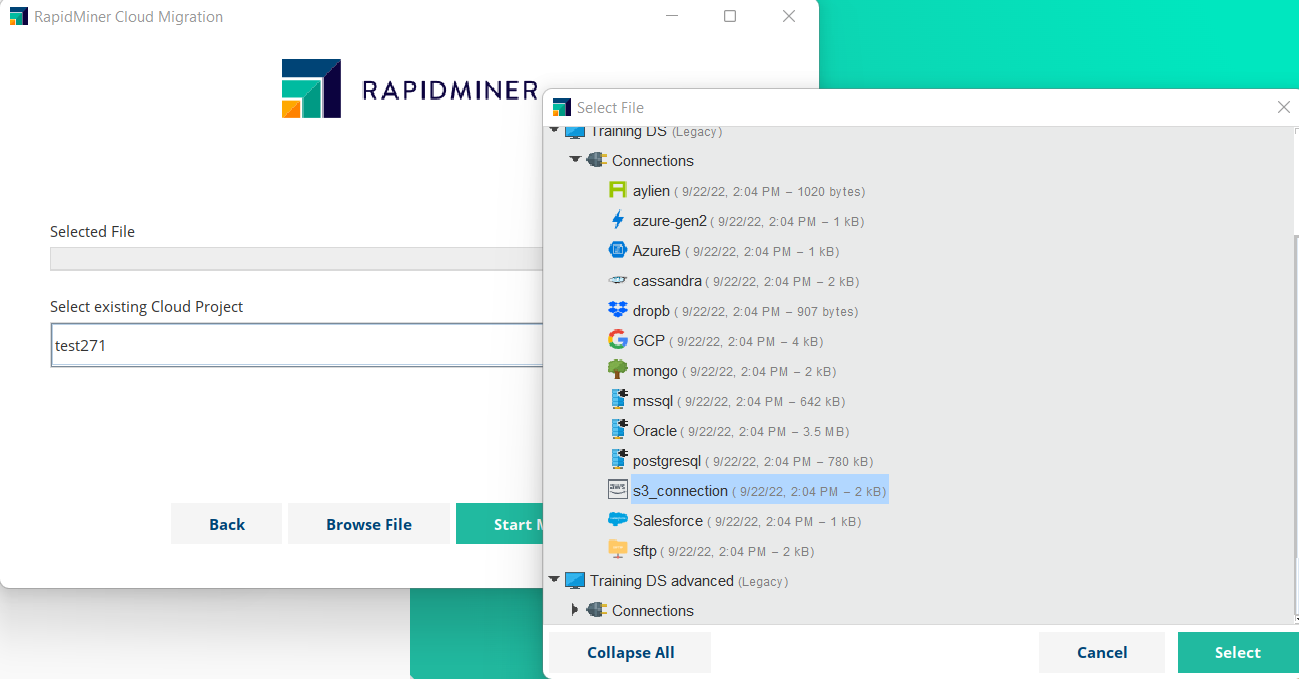

When the migration is completed, go to your Cloud project to inspect the Connections tab.
To edit a connection, you need to follow the same two steps: edit in RapidMiner Studio, then upload using the migration tool.
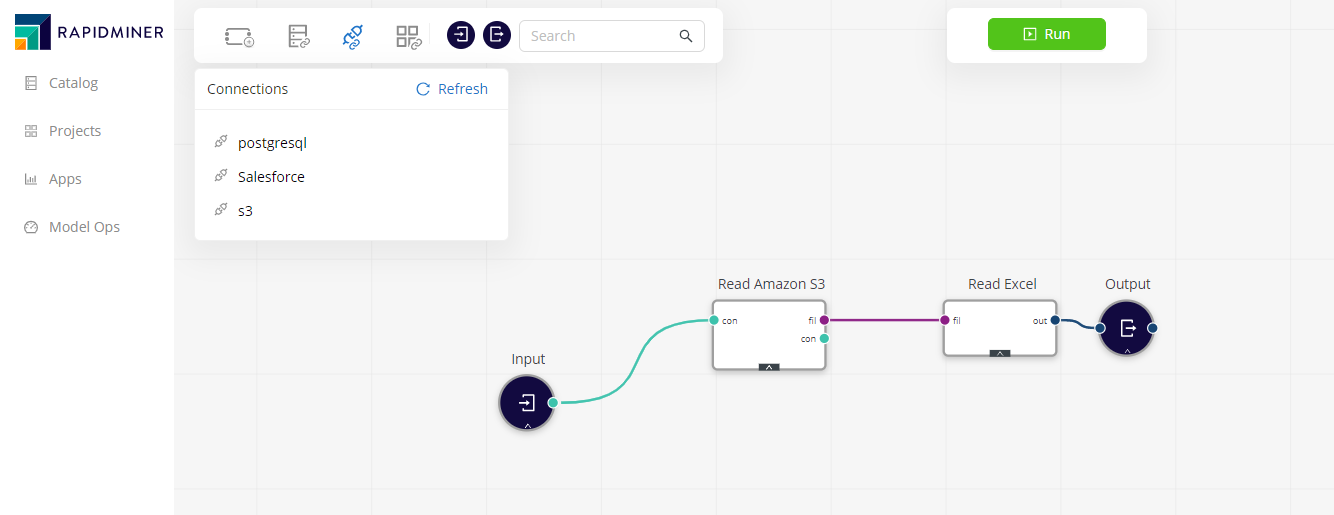
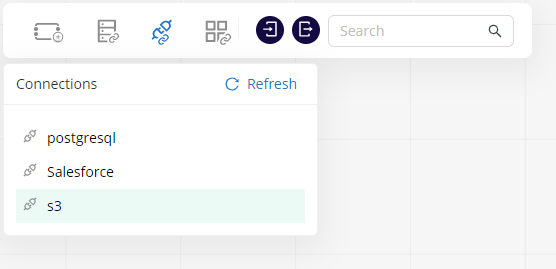
Use connections
Once the connection is part of your project, you can use it in any workflow. If you open or create a workflow, you can select it from the connections list and drop it anywhere in the canvas.
The connection operator will have a connection object as the output, which can be connected to the appropriate reading operator (Read Database, Read Amazon S3, etc). Please read the help panel of each particular connection operator for the configuration details.