Model Ops
This document describes the life cycle of a Data Science project and some best practices: how models are created and deployed, and how you can monitor them afterwards.
The following document, Monitor a model, describes the Model Ops tools used to monitor your models once they are deployed.
The life cycle of models
Data Science projects start with understanding the problem that needs to be solved using existing or proposed data. This can be any business problem in multiple verticals, including predictive analytics in manufacturing, fraud detection in finance, sales forecasting, quality prediction, and many others.
As data is the basis for everything, the immediate task is to collect and prepare data. Once data is available, the next step is to train models based on the data to capture the behavior: how the company's sales depend on marketing campaigns, how the quality of a manufactured product relates to the conditions and parameters that were used in its productions, and so on. The model will internally contain correlations and the general behavior that helps us predict future outcomes.
Once the model is trained, one needs to validate how good it is, to answer the main question: will it be reliable in production? RapidMiner provides multiple validation and performance operators to help you with that, with no code needed.
Once we can trust it, it's ready to be deployed, which means that it becomes part of the more global corporate processes.
In most software projects, that would be the endpoint, but not in Data Science. Data Science projects are always circular: once in production, the model needs to be monitored, and eventually retrained and re-deployed to keep up with any changes in those behaviors it captured.
But let's take a look at each of those tasks in RapidMiner.
Collect and prepare data
RapidMiner provides a very flexible framework for data ingestion and preparation. There is a data catalog where any generated data can be stored, or external datasets can be uploaded. Once there, users have full flexibility to decide which projects can use them or who to share them with.
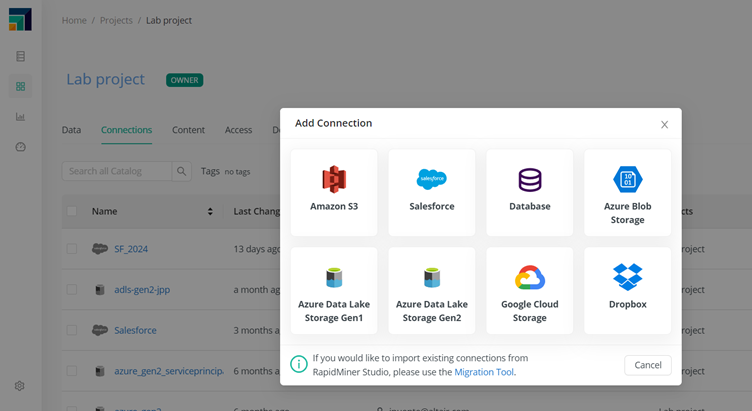
But in most cases, data stays wherever it is, be it internal data sources or cloud repositories. For all those, RapidMiner has the appropriate means to access, browse, read from or write data to. In particular, users or admins can create connections to relational databases, AWS S3 buckets, Azure Blob Storage, Google Storage, Dropbox and others. Data can stay there and be read and manipulated only when needed.
That's the life cycle of data: it's read, transformed, and stored back again in any of the multitude of supported data sources.
Train models
Once data is ready, it's time to train the models, and RapidMiner includes a good number of options to use in the no-code Designer or as Python code. Models are stored in a project, where access can be controlled.

Before using them in a production environment, models should be validated using, for instance, the Cross Validation operator, to make sure they are accurate enough, and they don't have any unexpected bias.
But this is not the end of the model's life cycle, it's rather the beginning.
Deploy models
Now that we have some models, it's time to use them in production, that is, to help us solve a business problem and create a positive business outcome.
For that, typically, the model is used to score data (make predictions) either periodically, using schedules, or on-demand, using what we call deployments.
Schedules run a workflow periodically, it may be every minute, every day at 5pm, or every Wednesday afternoon. Usually, the results of the run are stored back into the repository or any other data storage. This might be the end report someone needs to use, or, more often, the starting point of some other process.
Deployments publish wokflows and models as APIs. Some external script or process sends an HTTP request, and the prediction is sent back as a result. This can be used, for instance, to create a dashboard in Altair Panopticon or a third-party dashboarding or BI tool. This way, the outcome of the model becomes public and usable. Alternatively, predictions can be requested by any other application (java, python or in any other language) to use them whenever the use case so requires.
Closing the loop: Model Ops
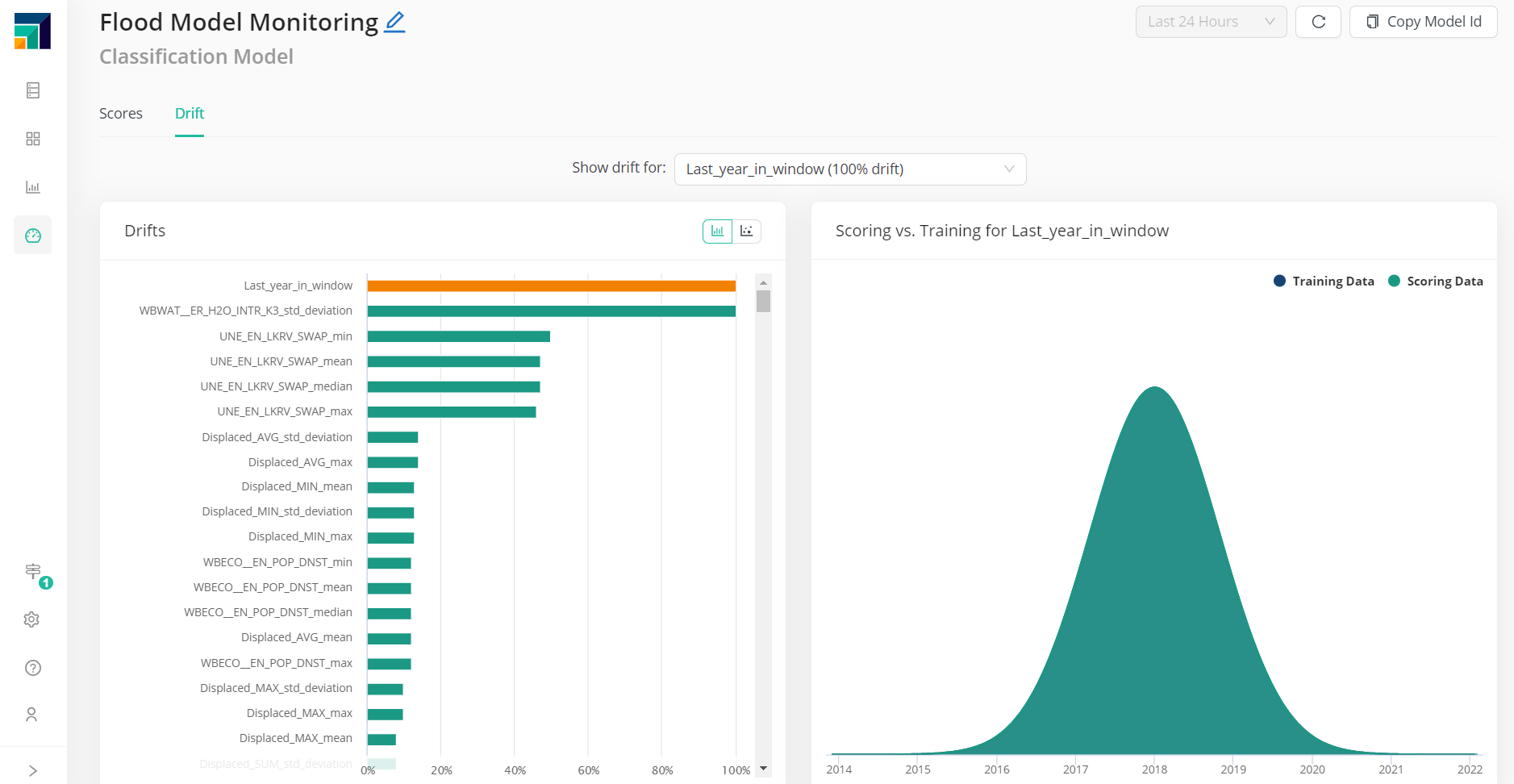
But that's not really the end of the model's life cycle. Models embed business behavior, from how our customers buy to how certain pieces of equipment fail in some conditions. Such behavior tends to change with time, if circumstances change or if we influence processes as they evolve. This means that we need to constantly monitor the performance of models, re-train and re-deploy as needed.
RapidMiner provides the right tool to close the loop: the Model Ops application.
Some conclusions
This loop of understanding the problem, modeling, deploying, monitoring, improving, and re-deploying becomes the virtuous cycle that helps us not only solve our problem, but make sure it improves with time. RapidMiner has just the tools to help you get it right.