Execute Python
The Execute Python operator enables a smooth integration of your Python code into your Altair AI Cloud workflows. Your Python code may live inside the operator or outside the operator:
- either in the Data Assets
- or within a project.
-
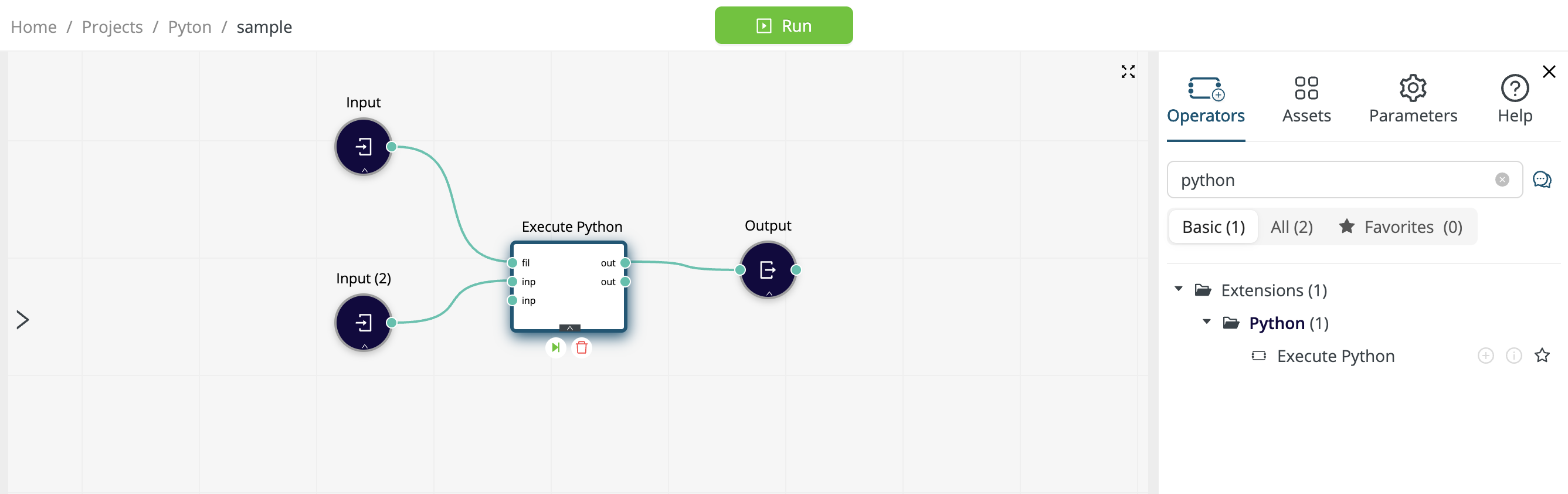
At the input ports (inp), Altair AI Cloud data tables are converted to Pandas DataFrames.
-
At the output ports (out), Pandas DataFrames are converted back to Altair AI Cloud data tables.
-
The fil port gives the operator access to Python code that is stored in the Data Assets or in the Git repository connected with a project. Alternatively, you can paste your Python code directly into the editor provided by Execute Python.
-
Your Python code must be structured as a function called
rm_main(data1, data2, ...), with an arbitary number (possibly zero) of inputs and outputs. Each input or output ofrm_main()is a Pandas DataFrame.- The number of input and output Pandas DataFrames in
rm_main()must be equal to the number of connected ports on Execute Python. In the screenshot above,rm_main(data1)accepts a single Pandas DataFrame as input and returns a single Pandas DataFrame as output. - If there are macros defined, the number of arguments in
rm_main()should be the number of connected input ports plus one. The macros argument must take the form of a dictionary.
- The number of input and output Pandas DataFrames in
In what follows, we discuss the parameters of the Execute Python operator.
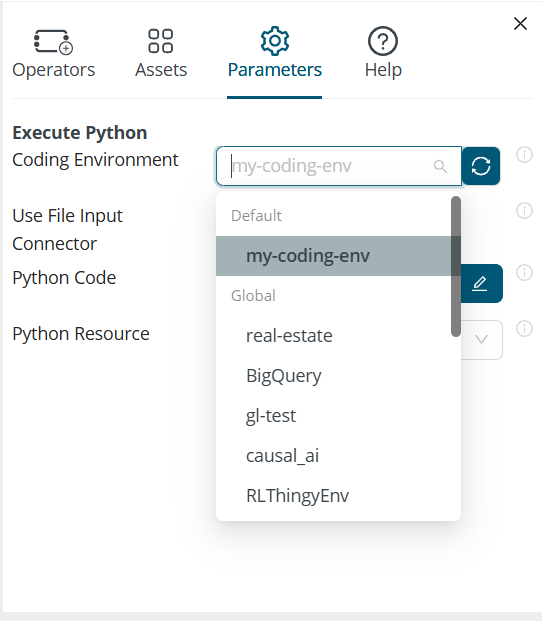
Coding Environment
When your workflow includes the Execute Python operator, the coding environment defines which Python packages are available to your Python code. If you have multiple Execute Python operators in your workflow, each of them can have its own coding environment.
The default Python coding environment is called rm-base, but you are free to use an alternative coding environment, so long as it includes Pandas and PyArrow. Only coding environments that include PyArrow will appear in the Coding Environment dropdown list.
Use File Input Connector
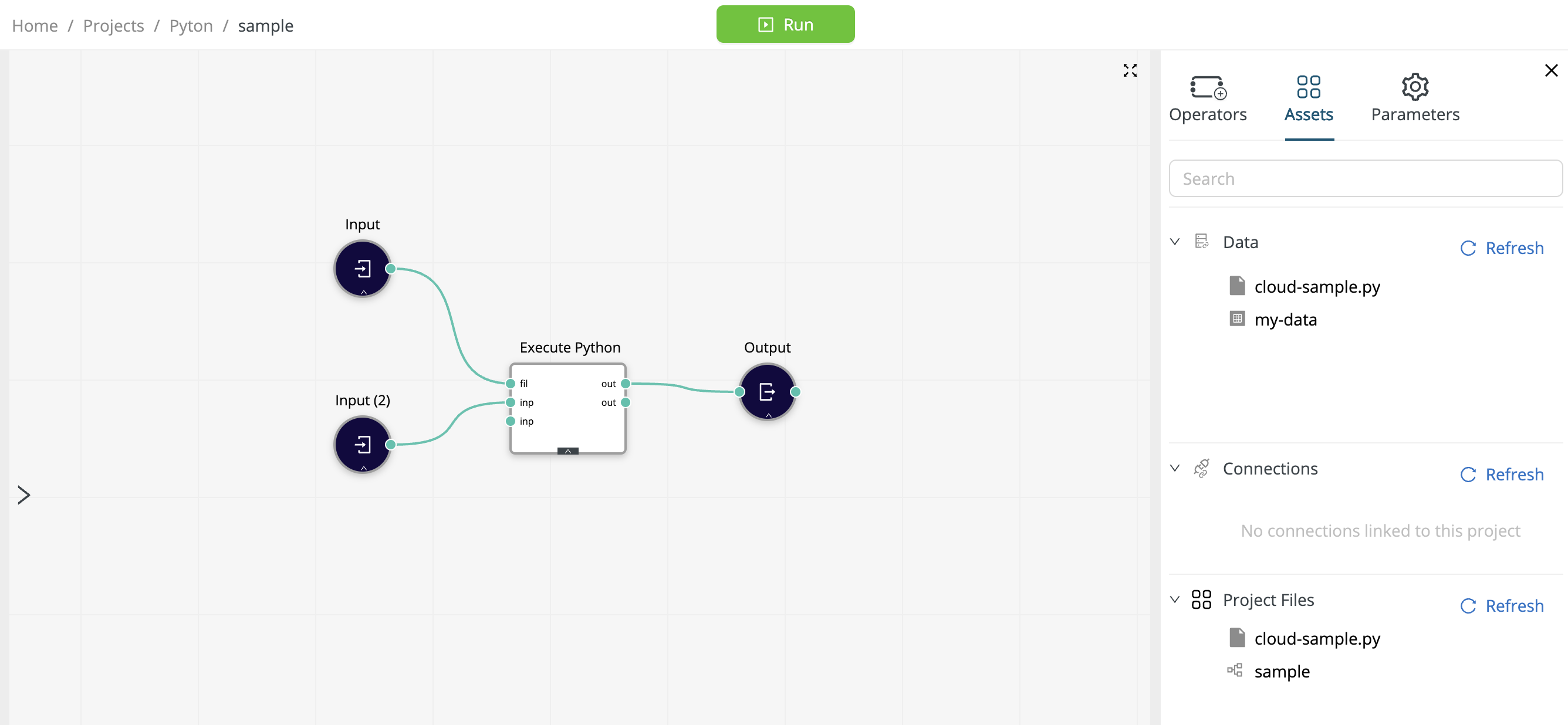
Recall that the Data Assets may contain any sort of file, not merely data files.
Suppose you want to execute a Python program that lives outside of the Execute Python operator.
- You might have uploaded the file to the Data Assets.
- Alternatively, you might have created the the code in a Web IDE and pushed it to the Git repository connected to a project.
In either case, with the focus on the Execute Python operator, the file will appear under Assets:
- in the Data category if you uploaded the file to the Data Assets
- in the Project Files category if pushed the file to the project via a Workspace
Your Python program is external to the Execute Python operator, so take the following steps:
- drag the file (e.g. cloud-sample.py) to the canvas,
- attach the resulting Input to the fil port, and
- with the focus on Execute Python, click on Parameters and enable the parameter Use File Input Connector.
Python Code
Hint: if you have two versions of your Python code, you can have one program external to the operator (as described above) and one program internal to the operator (as described below) and toggle them via the switch Use File Input Connector.
Alternatively, if you wish to paste your Python code directly into the Execute Python operator without creating an external file, click on Parameters, disable Use File Input Connector, and select Python Code.
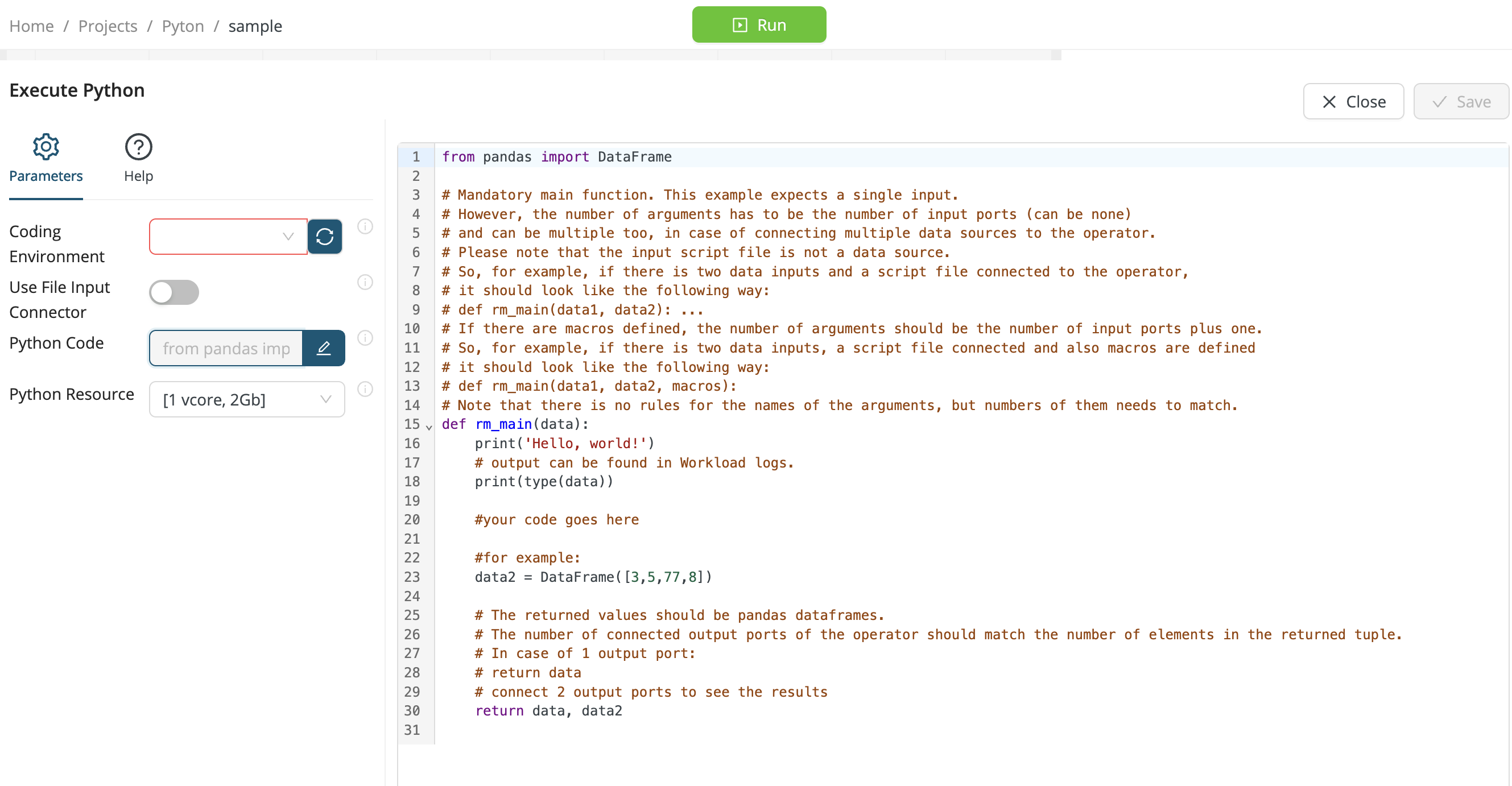
Under Parameters > Python Code, click on the Edit button to reveal the following sample Python code, then replace it by your own code. Note the helpful comments.
from pandas import DataFrame
# Mandatory main function. This example expects a single input.
# However, the number of arguments has to be the number of input ports (can be none)
# and can be multiple too, in case of connecting multiple data sources to the operator.
# Please note that the input script file is not a data source.
# So, for example, if there is two data inputs and a script file connected to the operator,
# it should look like the following way:
# def rm_main(data1, data2): ...
# If there are macros defined, the number of arguments should be the number of input ports plus one.
# So, for example, if there is two data inputs, a script file connected and also macros are defined
# it should look like the following way:
# def rm_main(data1, data2, macros):
# Note that there is no rules for the names of the arguments, but numbers of them needs to match.
def rm_main(data):
print('Hello, world!')
# output can be found in Workload logs.
print(type(data))
#your code goes here
#for example:
data2 = DataFrame([3,5,77,8])
# The returned values should be pandas dataframes.
# The number of connected output ports of the operator should match the number of elements in the returned tuple.
# In case of 1 output port:
# return data
# connect 2 output ports to see the results
return data, data2
Python Resource
You can modify the default setting if your Python code requires additional resources -- if, for example, you have a complex workflow or huge data files.
- 1 vcore, 2 GB (default)
- 2 vcore, 4 GB
- 4 vcore, 8 GB
- 8 vcore, 16 GB
The following message provides a strong hint that you should modify this setting.
PyRunner instance is out of memory, please select one with more resources