Monitor a model
This document describes how Model Ops helps you monitor and constantly improve your models and workflows.
When a model is deployed, be it as a schedule or as a deployment itself, it starts to be used in production. That's when we can really know whether the model is behaving as we expect and solving the business problem we trained it for. That's where the monitoring provided by Model Ops is key.
Let's see how it's done.
Collect initial data during training
The Model Ops tool in Altair AI Cloud provides model monitoring and creates dashboards to analyse key metrics such as the evolution of class distribution, scoring time, number of scores, and input data drift.
In order to get the initial data, one needs to first register a model.
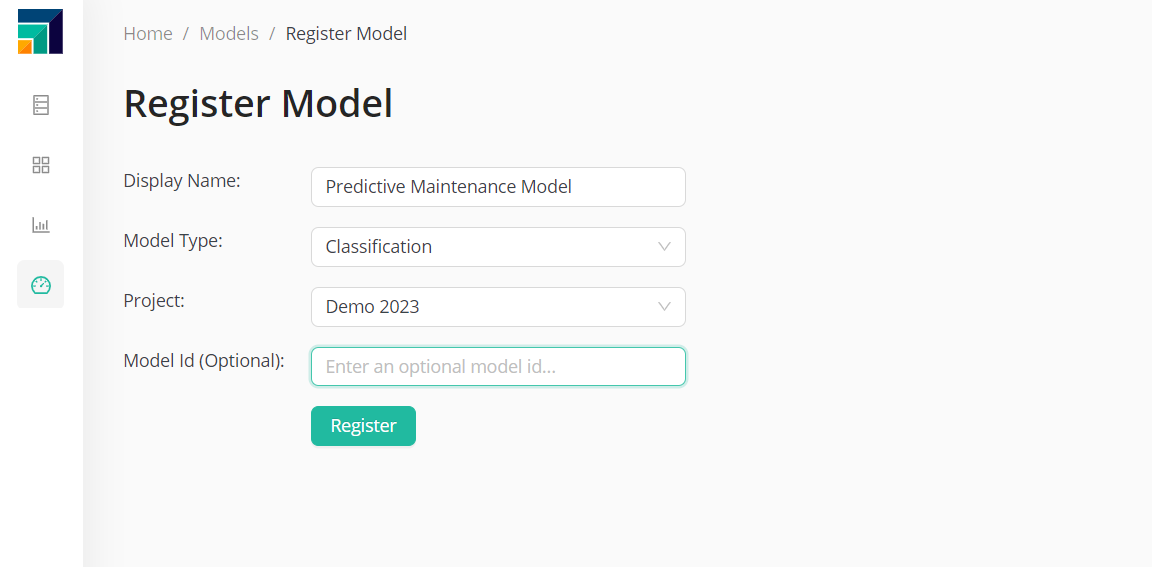
The Model ID can be either typed by the user or generated by the tool. This ID will be later used to identify this particular model.
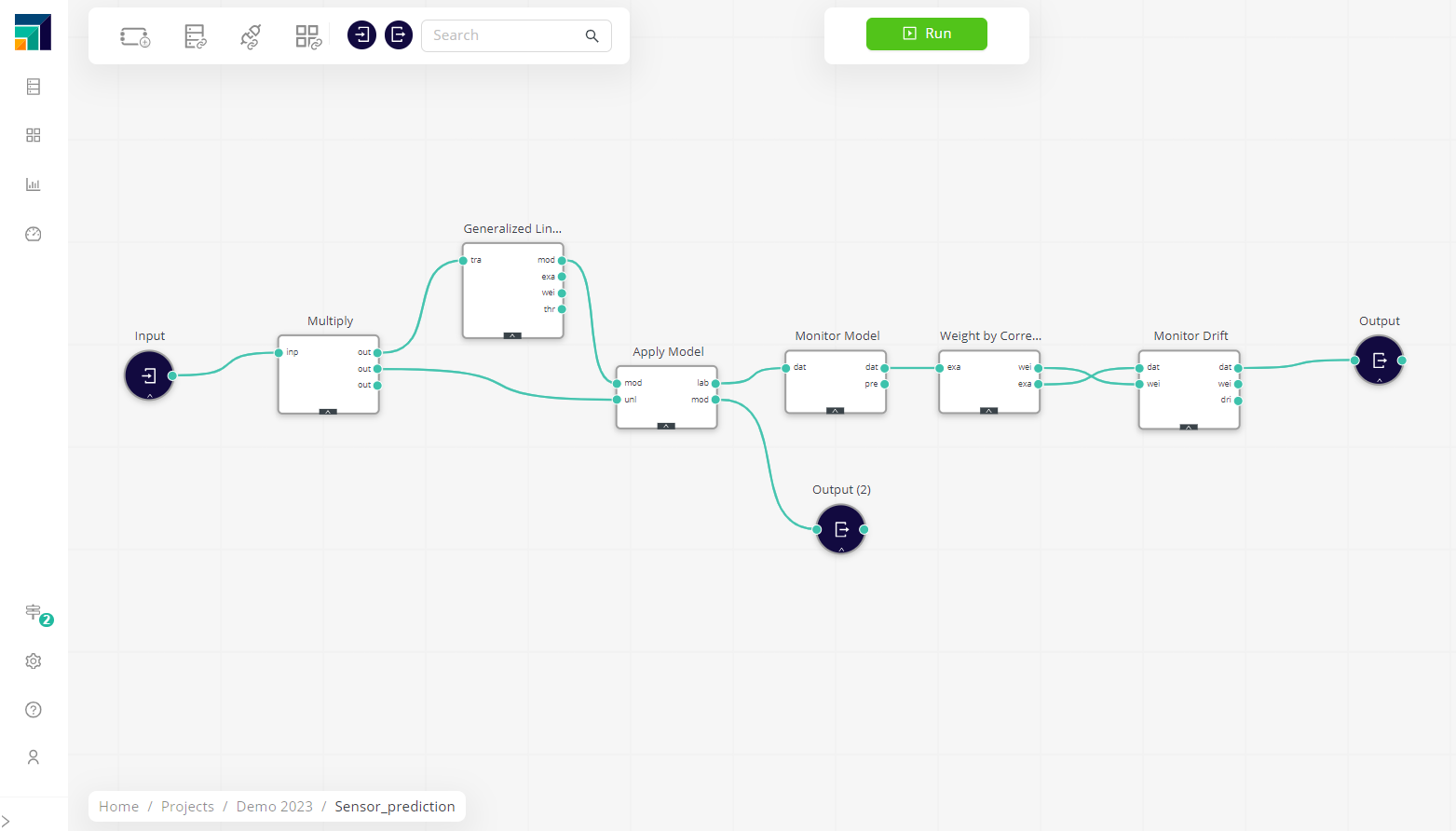
Then, at training time, the Monitor Drift operator can be used to send the initial input statistics to be compared with later scoring runs. The Model ID created when it was registered needs to be provided to link the monitored information with the right model. As an optional input, one can add weights (calculated using Weight by correlation, for instance). If weights are added, those can also be compared with those of the future scoring data.
Collect data during scoring
During model scoring, the Monitor Drift and Monitor Model operators need to be added (with the right Model ID) for Altair AI Cloud to automatically send new, current statistics to Model Ops every time the workflow is run (as part of as schedule or a deployment).
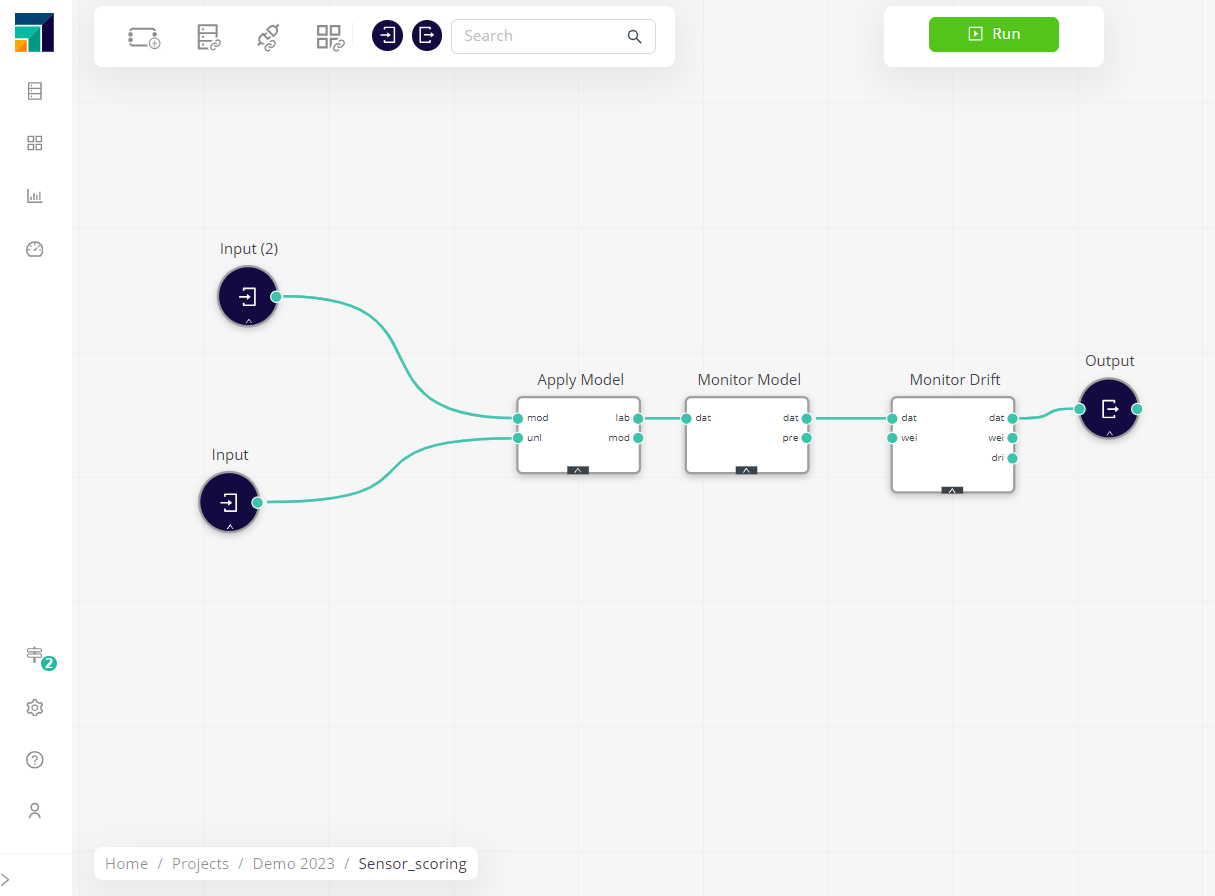
Monitor the data
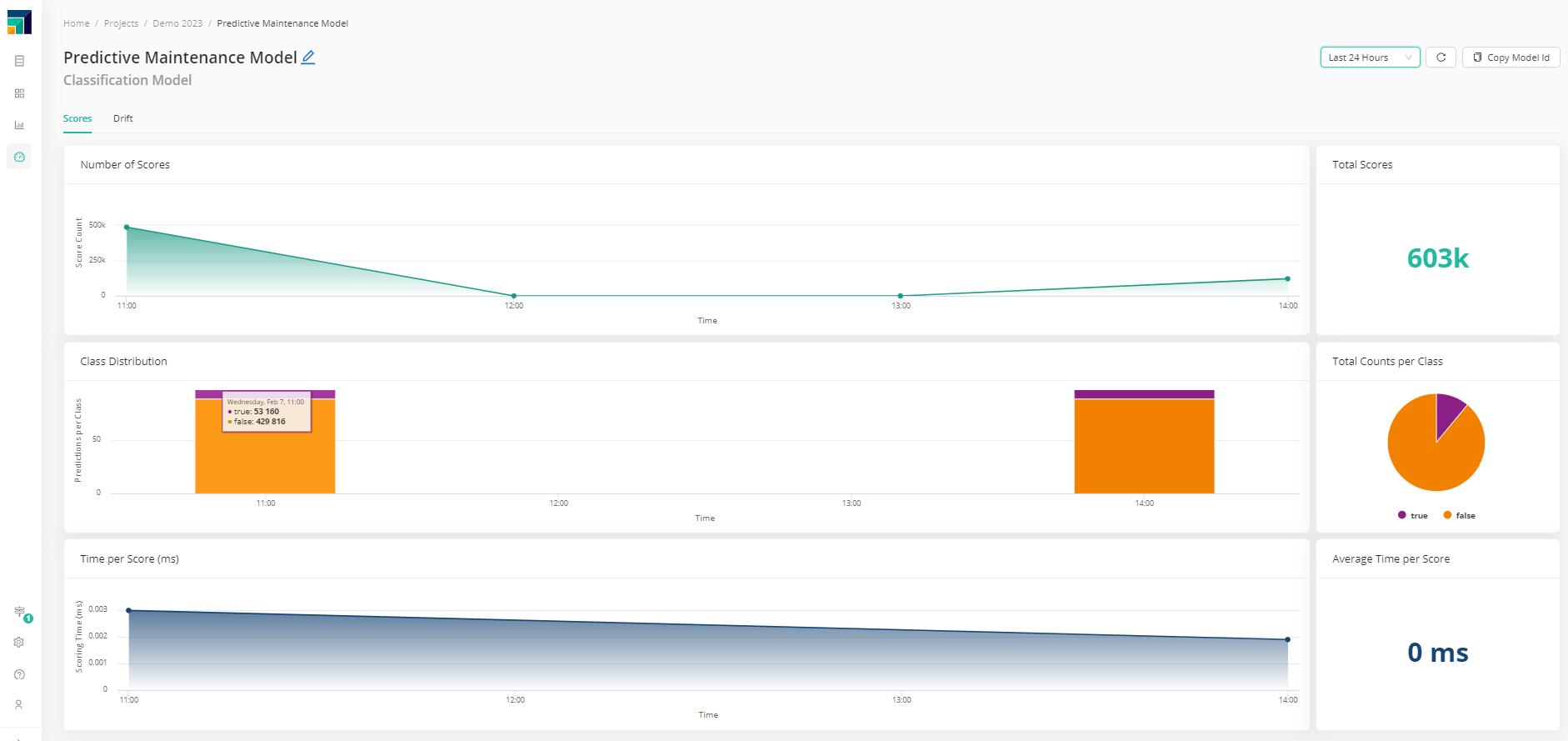
Model monitoring dashboards are produced where users can analyze the evolution of the model's behavior, to understand when it's separating from the initial conditions and when re-training and re-deployment are needed.
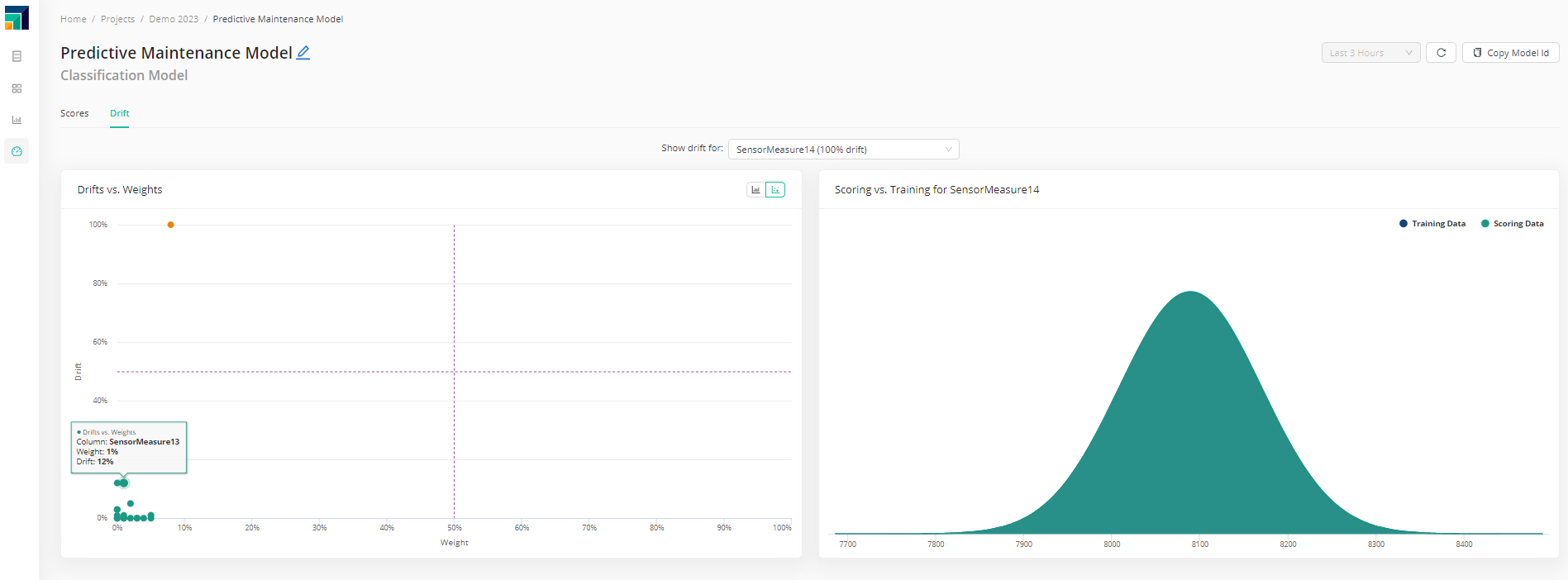
Scoring information is presented, like the timeline of the number of scores, class distribution and it's evolution, as well as how much time each score takes.
Drift is another key element. How different is the data the model is scoring now, compared to the one it was trained with? If this diverges too much, it's time for re-training and re-deploying.
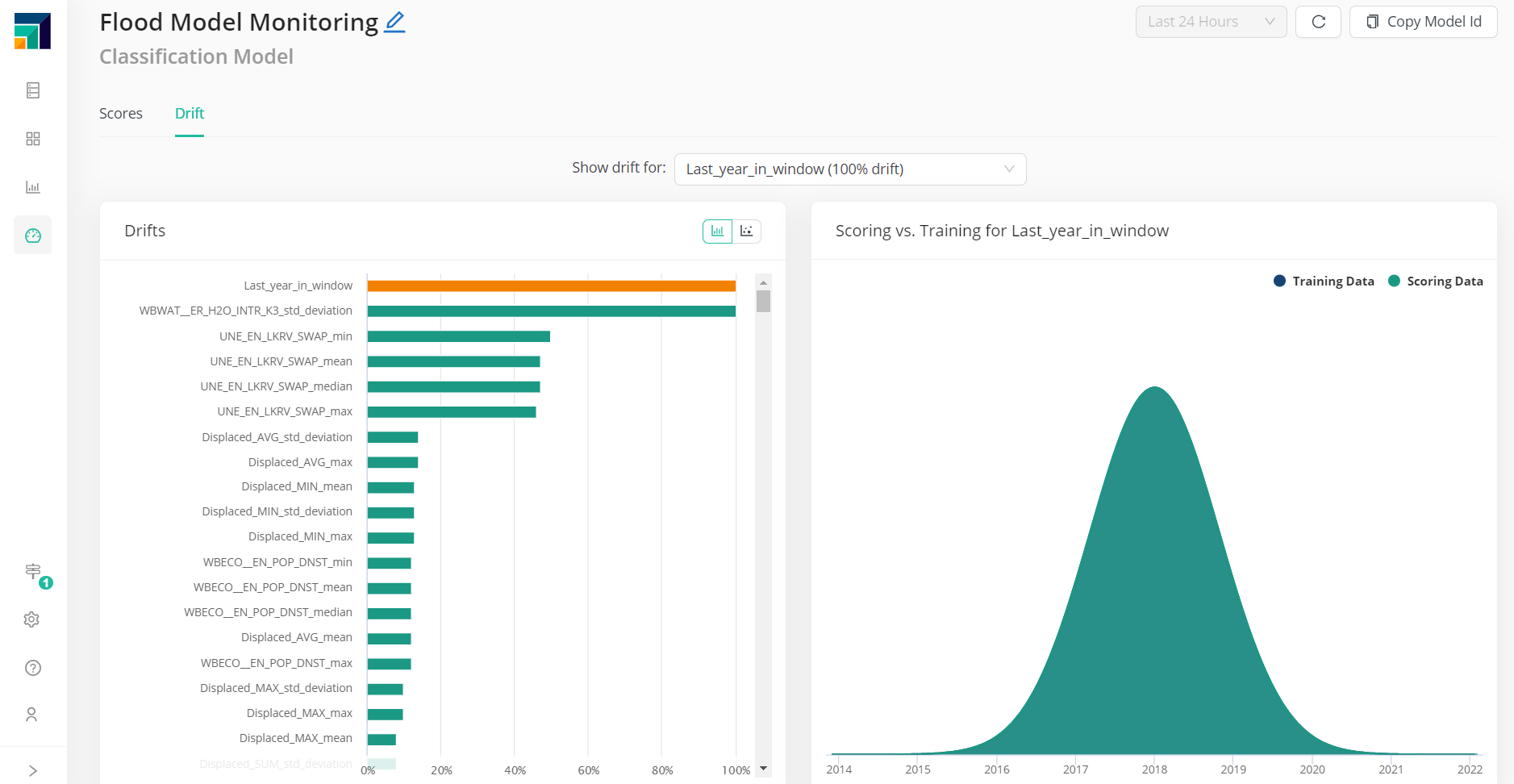
If weights were initially added during the training, it's also possible to check the weight vs. drift relation.